KafkaとKubernetes
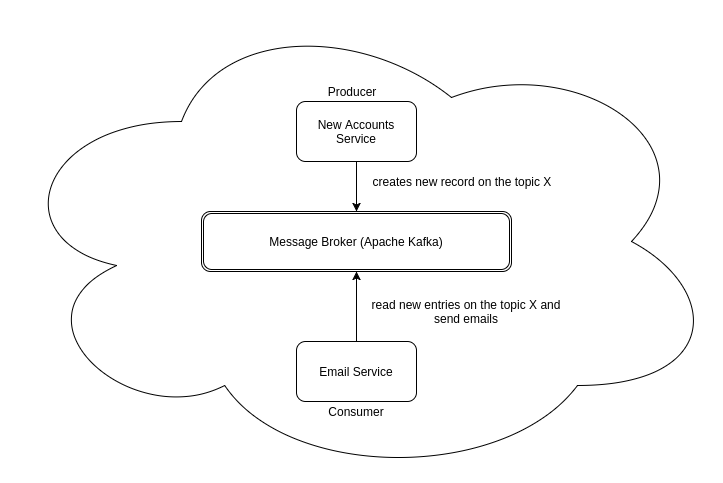
メッセージングシステムは昔からいろいろな用途で使われてきましたが、近年のモダンなサービス開発という流れでもその重要性は大きくなっています。
マイクロサービス間の非同期な連携とか、イベントソーシングなアプリのイベントストア、分散システムのログ集約などなど様々ですね。
Kubernetes上でマイクロサービスを作成する場合も、kubernetesクラスタ上にKafkaをインストールしてサクッと使ってみたいものです。
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63
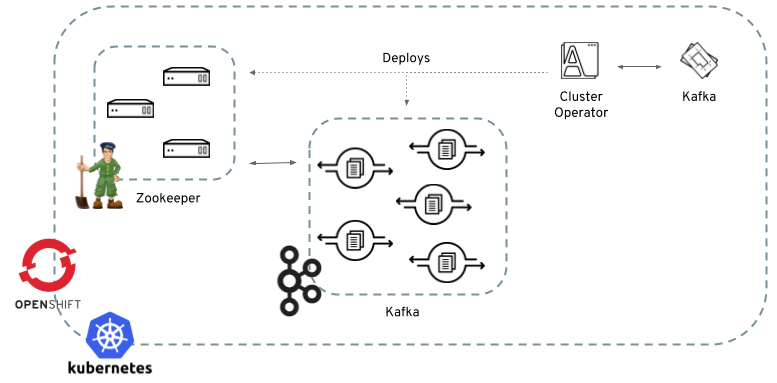
しかしKafkaは、Kafkaのプロセスだけでなくzookeeperのクラスタも構築して保守してやる必要があったり、そもそもステートフルだったりで、kubernetes上でデプロイ、保守するのはとても敷居が高いものでした。
そこを解決するのがstrimziというOSSです。
strimziは、operatorという仕組みでkubernetes上のKafkaクラスタの管理を大幅に省力化します。
operatorに関しては、 https://pocketstudio.net/2016/11/10/introducing-operators-translate-jp/ あたりが参考になります。
その実体は、 Kubernetesにデプロイされたコンテナ です。
KubernetesのAPIでイベントを監視して、コンテナをデプロイしたり設定したりバックアップしたりといった保守作業を行うコンテナのことをoperatorと呼びます。
strimziでは、以下3つのoperatorを提供しています。
- Cluster Operator
KafkaというCustom Resourceの状態を監視して、zookeeperやKafkaのデプロイ、設定、保守を行う
- Topic Operator
KafkaTopicというCustom Resourceの状態を監視して、Cluster Operatorが保守しているKafka上にtopicを作成したり削除したり設定変更したりする - User Operator
KafkaUserというCustom Resourceの状態を監視して、Kafkaのユーザーを管理する
{kind=link}
つまり、strimziを使うと、以下のようなyamlを、
|
|
kubectl -f kafka-cluster.ymlというように適用するだけでkubernetes上にKafkaをプロビジョニングできるということです。便利ですね。
そういうわけで、さっそくローカルのk8s環境で試してみましょう。
minishiftにKafkaをoperatorでインストールする
strimziがサポートしているKubernetes環境は、Kubernetes 1.9以上またはOpenShift3.9以上とのことです。
http://strimzi.io/docs/0.7.0/#getting-started-str
今回は、minishiftでローカルにOpenShift環境を立ち上げて試してみます。
minishiftのインストールはこちらを参照してください。
https://docs.okd.io/latest/minishift/getting-started/installing.html
インストールしたら、以下コマンドでローカルにOpenShiftを立ち上げます。
何となくメモリたくさん使いそうなので、6GB割り当てるようにしました。
|
|
これ以降の手順ではclusterスコープのCRDを設定したりする関係上、cluster-admin権限が必要なので、とりあえずsystem:adminでログインしておきます。
strimziのダウンロード
strimziをGitHubからダウンロードします。
https://github.com/strimzi/strimzi-kafka-operator/releases
strimziのCluster Operatorをインストールする
Kafkaのクラスタをインストール、設定してくれる、strimziのCluster Operatorをインストールします。
|
|
Cluster OperatorでKafkaのクラスタをインストールする
Cluster Operatorがインストールされれば、それを使ってKafkaのクラスタをインストールできます。
Cluster Operatorは、project(namespace)内のイベントを監視しており、ここにKafka(CR, Custom Resource)を作成することでKafkaのクラスタをインストール、設定してくれます。
Kafka(CR)は、yamlの例が「examples/kafka」に格納されています。
- examples/kafka/kafka-ephemeral.yaml
- 永続ストレージを割り当てない揮発性のKafkaクラスタ(検証用)
- examples/kafka/kafka-persistent.yaml
- 永続ストレージを割り当てたKafkaクラスタ
今回は、検証用にephemeralなほうをインストールします。KafkaCRは以下のような形式です。
|
|
なんとなく、どんなクラスタができるか想像できますね。このCRをKubernetes上に作成します。
|
|
上記のようにkafkaリソースが作成されたら、Cluster Operatorがkafkaリソースの定義に従ってKafkaのクラスタをセットアップしてくれるので、それを確認します。
|
|
このように、Kafkaとzookeeperがインストールされていることを確認できます。
Topic Operatorで、KafkaクラスタにTopicを作成する
strimziは、Kafkaクラスタそのものを保守するCluster Operator以外にも、Kafkaクラスタにtopicやuserを作ってくれるOperatorも設定されます。
Topic Operatorは、上記手順でインストールされた「my-cluster-entity-operator-xxxx」(Entity Operator)にあるので、すでに使える状態になっています。
さっそくTopic OperatorでKafkaクラスタ上にtopicを作成してみます。「examples/topic/kafka-topic.yaml」に例がありますが、以下のようなKafkaTopicというCRを作成することでTopic OperatorがKafkaクラスタ上にtopicを作成してくれます。
|
|
これを、以下のようにKubernetesクラスタに適用します。
|
|
これで、Kafkaクラスタにtopicが作成されます。
Kafkaクラスタにメッセージを投げてみる
さて、Kafkaクラスタがインストールされたので、このKafkaにメッセージをPublish/Subscribeしてみます。
strimziには、サンプルのクライアントも付いているので、簡単にKafkaクラスタを検証できます。
メッセージをSubscribeするクライアントを実行する
以下でメッセージをSubscribeしてみます。
|
|
上記コマンドを実行すると、Kubernetes上でサンプルクライアントが実行され、Kafkaのトピック「my-topic」をSubscribeする状態になります。
メッセージをPublishするクライアントを実行する ターミナルをもう一つ開いて、以下コマンドを実行します。
|
|
プロンプトが開くので、適当に文字列を入力してみてください。
|
|
すると、kafka-consumerの上で入力したメッセージが表示されるのを確認できるはずです。
|
|
まとめ さて、Kubernetes上にKafkaをインストールし、メッセージングプラットフォームを構築してみました。
実際には、JavaやRubyのクライアントからこのKafkaのトピックをPub/Subして非同期通信、マイクロサービスを実現したり、IoTなイベントを受けたり、ログ集約基盤を作ったりするわけです。
そういうわけで、次はJavaアプリからこのKafkaを使ってみます。