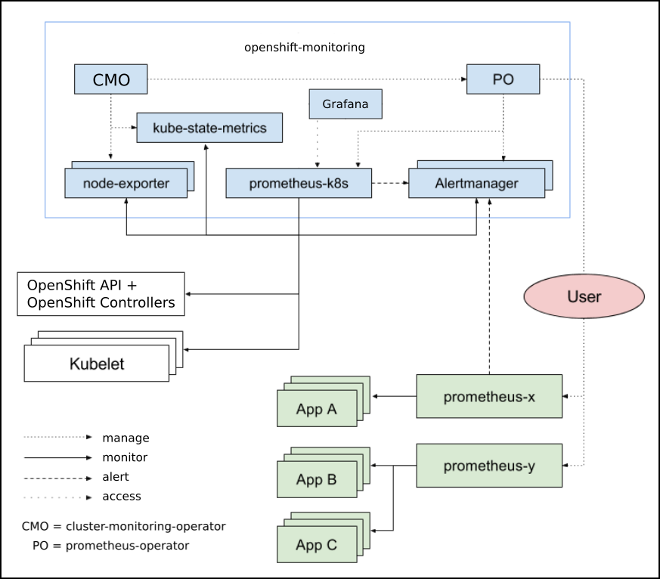
OpenShift v3.11から、Prometheusを中心とした監視スタック(Prometheus/Grafana/Alertmanager)がGAとなっています。
従来のOpenShiftの場合、Kubernetesやノードなど基盤の異常を通知するために別製品を導入する必要がありましたが、v3.11から単独でクラスタの監視、通知ができるようになったわけですね。
この記事では、OpenShiftがなんか壊れたときにメールで通知してもらうようにしてみます。
OpenShiftのPrometheus
OpenShiftでは、Prometheus監視スタックはCluster Monitornig Operator(CMO)というOperatorによりクラスタにインストールされ、Prometheus/Grafana/Alertmanagerの連携が設定され保守されます。
OpenShiftのクラスタの監視項目
OpenShiftでは、インストール時に以下の監視項目が設定されており、現在のところ監視項目自体をカスタマイズすることはできません。
https://docs.openshift.com/container-platform/3.11/install_config/prometheus_cluster_monitoring.html#alerting-rules
抜粋
| アラート名 |
深刻度 |
内容 |
| ClusterMonitoringOperatorErrors |
critical |
CMOのエラー率がxx% |
| AlertmanagerDown |
critical |
AlertMangerがPrometheusから見えなくなった |
| KubeAPIDown |
critical |
KubernetesのAPIがPrometheusから見えなくなった |
| KubePodCrashLooping |
critical |
システムプロジェクトで単位時間内にxx回再起動を繰り返している |
| KubeDeploymentReplicasMismatch |
critical |
システムプロジェクトでレプリカ数が定義と合っていない |
| KubeQuotaExceeded |
warning |
あるNamespace内でリソース使用量がx%以上になっている |
| KubeNodeNotReady |
critical |
ノードが1時間以上Not Readyになっている |
| KubeletTooManyPods |
warning |
Kubeletが動かしているPod数が多すぎる |
| DeadMansSwitch |
none |
常に送り続けるアラート(後述) |
最初からOpenShiftのAlertmanagerに設定されているのは DeadMansSwitchというアラートルールのみです。
これは、何もなくてもトリガーされ続ける特別なアラートルールで、監視システム自体が死んでいないか監視するために使われるものです。
PagerDutyなどを適切に設定すれば、 監視システムが死んでDeadMansSwitchが飛んでこなくなったときにアラートを上げる、といった使い方が可能です。
OpenShiftの監視項目の通知設定
OpenShiftの監視ルール自体はまだ変更できませんが、通知方法(Slack、メール、PagerDuty、etc..)は任意にカスタマイズ可能です。
OpenShiftのドキュメントにはAnsibleの変数で設定してPlaybookを実行するとありますが、Alertmanagerの設定はopenshift-monitornigプロジェクトのSecretsに入っているのでこれを変更すればよさそうです。
https://github.com/openshift/cluster-monitoring-operator/blob/master/Documentation/user-guides/configuring-prometheus-alertmanager.md
1
2
|
$ oc project openshift-monitoring
$ oc get secret alertmanager-main -ojson | jq -r '.data["alertmanager.yaml"]' | base64 -D
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
receivers:
- name: default
- name: deadmansswitch
|
このように、デフォルトではDeadMansSwitchを空打ちしているだけですので、これを変更して、エラーを繰り返しているPodがあったときにメールを飛ばすようにしてみます。
OpenShift監視からの通知設定を変更する
上記の設定を変更し、Gmailにメールを飛ばすには以下のようにします。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: deadmansswitch
- match: # 追加
alertname: KubePodCrashLooping
repeat_interval: 5m
receiver: email-admin
receivers:
- name: default
- name: deadmansswitch
- name: email-admin
email_configs:
- to: "xxx@example.com" # 送信したいアドレス
from: "xxx@gmail.com" # gmailアドレス
smarthost: smtp.gmail.com:587
auth_username: "xxx@gmail.com" # gmailアドレス
auth_identity: "xxx@gmail.com" # gmailアドレス
auth_password: "xxxx" # Googleアカウントのパスワード
|
KubePodCrashLooping は、「システムプロジェクト(openshift-*/kube-*/default/logging)内のPodが再起動を繰り返している状態が1時間以上続くとアラートを発行する」というルールのようです。
https://github.com/openshift/cluster-monitoring-operator/blob/master/assets/prometheus-k8s/rules.yaml#L621
1時間待つのはつらいので、以下のルールも適用して通知がGmailの通知設定が正しいことを確認します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
global:
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: default
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 5m
receiver: email-admin # DeadMansSwitchの送信先をGmailにする
- match:
alertname: KubePodCrashLooping
repeat_interval: 5m
receiver: email-admin
receivers:
- name: default
- name: deadmansswitch
- name: email-admin
email_configs:
- to: "xxx@example.com"
from: "xxx@gmail.com"
smarthost: smtp.gmail.com:587
auth_username: "xxx@gmail.com"
auth_identity: "xxx@gmail.com"
auth_password: "xxxx"
|
さて、この設定をOpenShiftのAlertmanagerに反映しましょう。このyamlファイルを任意の名前で保存して、以下コマンドで元のSecretを置き換えます。
1
2
|
oc project openshift-monitoring
oc create secret generic alertmanager-main --from-literal=alertmanager.yaml="$(<my-alertmanager-rules.yaml)" --dry-run -oyaml | oc replace secret --filename=-
|
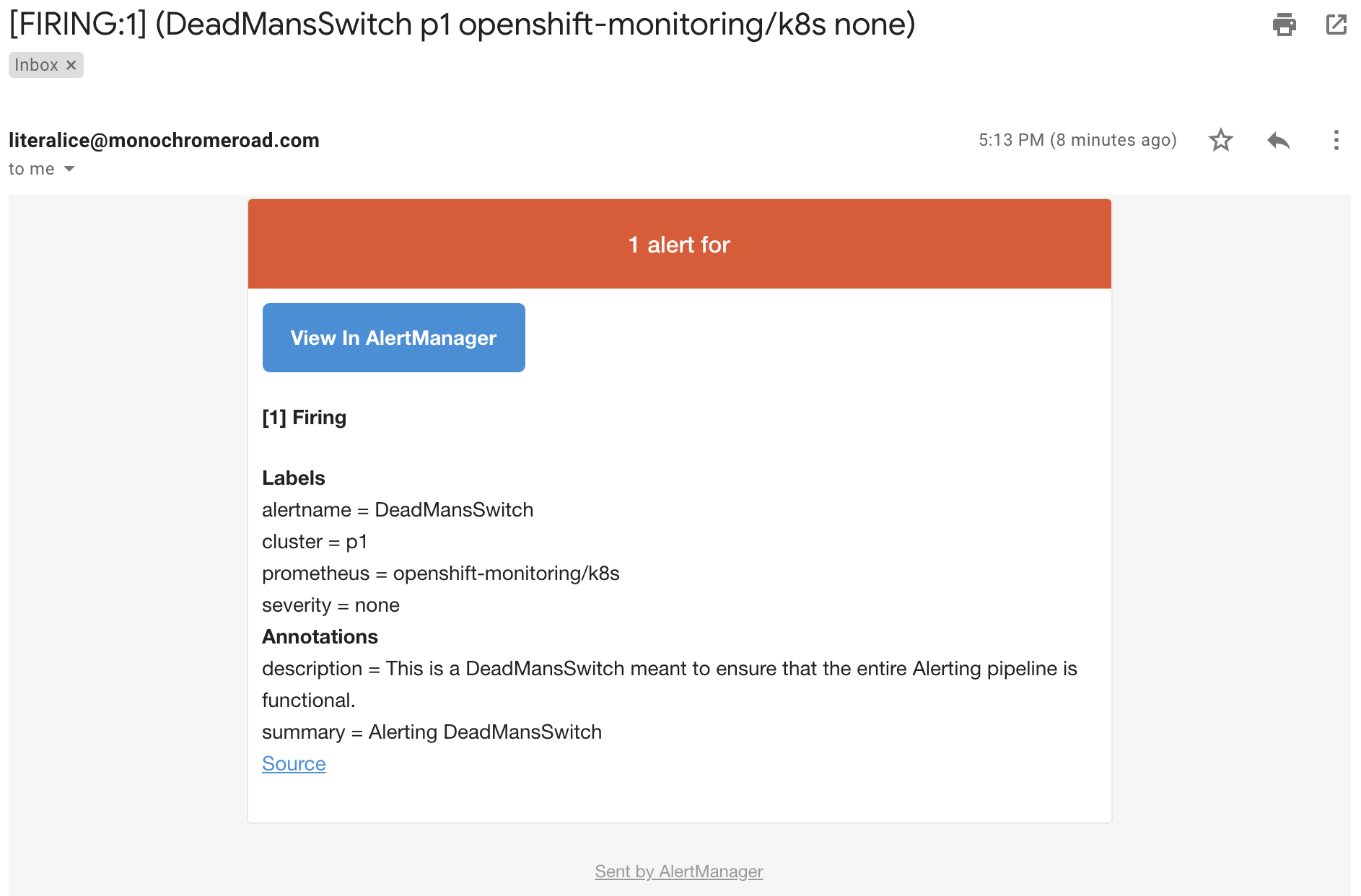
DeadMansSwitchルールは、常にトリガーされつづけているルールなので、設定が正しければgmailのほうに通知が届くはずです。
もちろん、DeadMansSwitchの本来の利用方法はこういうものではありません。
Dead Man’s Snitchのようなサービスと連携して、「通知が来ない状態が続いたら通知する」というふうに逆転させて使うものです。
エラーを発生させて通知が来ることを確認する
メールが飛んでいることを確認できたら、試しに、エラーを発生させてみてちゃんと通知が来るか確認してみましょう。次のようなDeploymentConfigでOpenShiftにコンテナをデプロイします。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
labels:
app: error-app
name: error-app
spec:
replicas: 1
selector:
app: error-app
template:
metadata:
labels:
app: error-app
spec:
containers:
- image: quay.io/literalice/error-image:latest
name: error-app
|
上記でデプロイしているコンテナは、単に即死するだけのこんなアプリ(?)です。
1
2
|
FROM registry.access.redhat.com/rhel7/rhel-atomic
CMD exec /bin/bash -c "sleep 1 & exit 1"
|
では、これをデプロイしてCrashLoopを監視対象であるdefaultプロジェクトで発生させます。
1
2
3
4
5
6
7
8
9
10
|
$ oc apply -f deployment.yaml -n default
deploymentconfig.apps.openshift.io/error-app created
$ oc get pods -w -n default
NAME READY STATUS RESTARTS AGE
docker-registry-1-dth48 1/1 Running 0 10d
error-app-1-deploy 1/1 Running 0 27s
error-app-1-xxjd9 0/1 CrashLoopBackOff 1 21s
registry-console-1-fvrt2 1/1 Running 0 10d
router-2-c27g5 1/1 Running 0 10d
|
CrashLoopが発生していますね。後は、この状態が1時間続けば通知が発行されます。
まとめ
簡単にOpenShiftクラスタの監視項目と通知の設定を見てきました。
PrometheusとAlertmanagerというデファクトスタンダードなプロジェクトを利用できる- 設定済みの豊富な監視項目から任意に選択して簡単に通知を飛ばしてもらうことができる
- 通知方法をカスタマイズできる
といったメリットがある一方、やはり監視ルール自体も追加、変更したくなりますね(技術的には可能ですが、v3.11現在はサポート対象の方法ではない)。
後の記事ではDeadMansSwitchについて詳しくみていきます。